It’s becoming common knowledge that list comprehensions are often considered the pythonic, more efficient/effective way of building lists, while doing some form of processing. This is in contrast to iterating over elements in a loop (typical habits that are formed when coming from programming in C/Java) and appending the items onto a list.
For algorithm challenges, I’ve found myself enjoying restructuring code to take advantage of this more visually aesthetic syntax, and along the way producing some one-liners that don’t feel forced (eye-sores).
This NYU article seems to identify the points associated with this consensus quoting 2 scenarios that list comprehension offers improvement:
- List comprehension is faster because it is optimized for the Python interpreter to spot a predictable pattern during looping.
- Besides the syntactic benefit of list comprehensions, they are often as fast or faster than equivalent use of
map.
There are several articles that would agree with these points, and the occasional disagreement that it provides nothing for performance, and is mostly just syntactically aesthetic (when done concisely).
Testing Environment
For this project, I’ve spun up Linode’s Nanode VPS to perform some tests. This ensures that the testing environment is as least chaotic (with minimal programs/services running) as it can be, while still returning realistic, repeatable results. Below is a snapshot of the new instance.
The version of Python being used is 3.7.3
The Timing Decorator
Functions in Python are first-class objects. This ultimately means that you can treat them as you would objects, such as passing them into other functions as a parameter.
A decorator is syntactic sugar which allows us to execute code both before and after the function it’s being applied on. It can be used in a variety of ways (caching/memoization, protecting views etc.). In this case we just need a start timer and end timer to perform timing analysis of the comprehensions we plan to test.
Since a decorator modifies how a function typically behaves (and applies its own function encapsulating the original function, @functools.wraps(func_name) helps preserve the metadata/details as explained here.
import functools
import time
def time_this(func):
@functools.wraps(func) # preserves metadata of original func
def wrapper_timer(*args, **kwargs):
start_time = time.perf_counter()
value = func(*args, **kwargs)
end_time = time.perf_counter()
func_run_time = end_time - start_time
print(f"Finished {func.__name__!r} in {func_run_time:.5f} secs")
return value
return wrapper_timer
List Comprehension Test Cases
There are several cases I want to explore:
Each case will have 1,000 10,000 100,000 1,000,000 and 10,000,000 samples to build a list with
- Randomly assorted numbers
- The base case of using a for loop and appending to a list
- Using list comprehension to populate a list
- Numbers increasing by a fixed/predictable amount
- The base case of using a for loop and appending to a list
- Using list comprehension to populate a list
- Applying a function on each sample (unordered)
- The base case of using a for loop and appending to a list
- Using a list comprehension to populate a list
- Using a lambda function within a list comprehension function (evaluating if there is any degradation using lambda syntax)
- Applying function to a list using map and casting the map to a list
Code Used in Test Cases Outlined
Section 1 of Test Cases - Random List being built
test_iterations = [1_000, 10_000, 100_000, 1_000_000, 10_000_000]
for test_case in test_iterations:
int_list = [x for x in range(test_case)]
shuffle(int_list)
print("Test Case: ", test_case)
@time_this
def loop_list():
answer = []
for num in int_list:
answer.append(num)
#return answer
loop_list()
@time_this
def list_comp():
answer = [num for num in int_list]
#return answer
list_comp()
Section 2 of Test Cases - Ordered List (Patterned) being built
test_iterations = [1_000, 10_000, 100_000, 1_000_000, 10_000_000]
for test_case in test_iterations:
print("Test Case: ", test_case)
@time_this
def loop_list():
answer = []
for num in range(test_case):
answer.append(num)
#return answer
loop_list()
@time_this
def list_comp():
answer = [num for num in range(test_case)]
#return answer
list_comp()
Section 3 of Test Cases - Applying Functions onto Lists
test_iterations = [1_000, 10_000, 100_000, 1_000_000, 10_000_000]
for test_case in test_iterations:
int_list = [x for x in range(test_case)]
shuffle(int_list)
print("Test Case: ", test_case)
@time_this
def loop_list():
answer = []
for num in int_list:
answer.append(num**2-3)
return answer
loop_list()
@time_this
def list_comp():
answer = [num**2-3 for num in int_list]
return answer
list_comp()
@time_this
def lamb_list():
answer = [(lambda x: x**2-3)(num) for num in int_list]
return answer
lamb_list()
@time_this
def map_list():
answer = list(map(lambda x: x**2-3, [num for num in int_list]))
return answer
map_list()
Results
Taking the average of 10 results produced in each section. The top row indicates how large of a list is being built. The first column briefly notes how the list was generated (based on test cases above). The data is time taken in seconds (s).
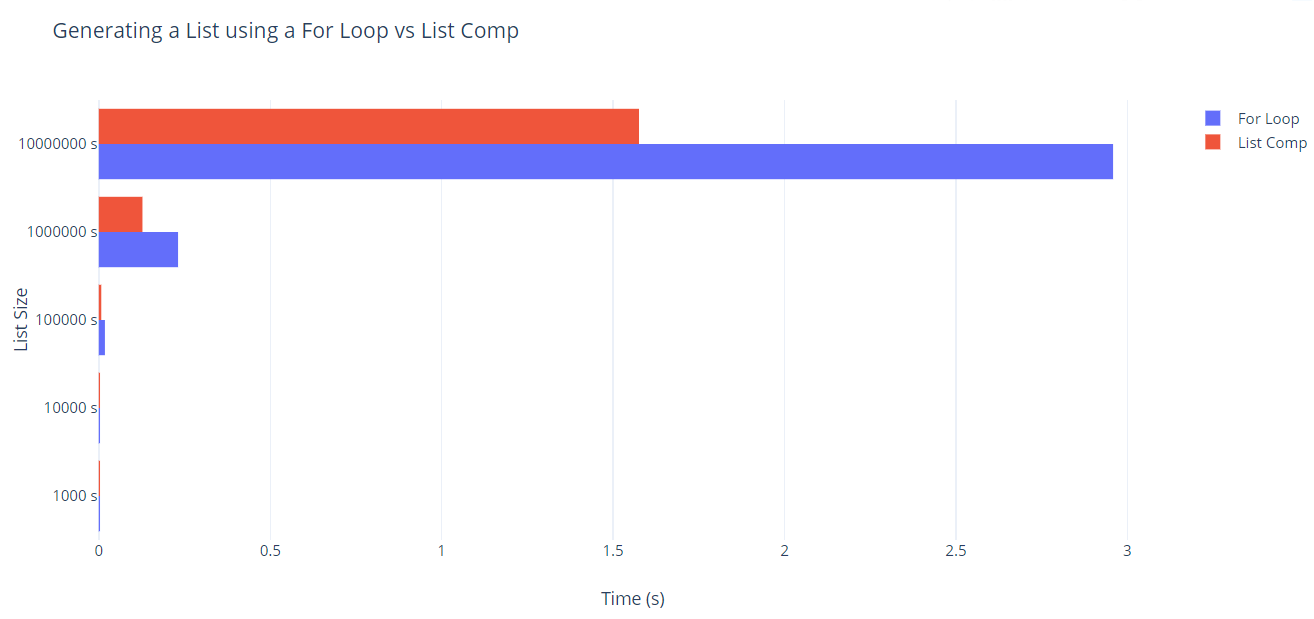
Section 1 Results
| 1,000 | 10,000 | 100,000 | 1,000,000 | 10,000,000 | |
|---|---|---|---|---|---|
| For Loop | 0.00011 | 0.00109 | 0.01793 | 0.23127 | 2.95845 |
| List Comp | 0.00005 | 0.00042 | 0.00569 | 0.12741 | 1.57571 |
List Comprehensions consistently performed approximately twice as fast as for loops, where the lists being generated consisted of random samples.
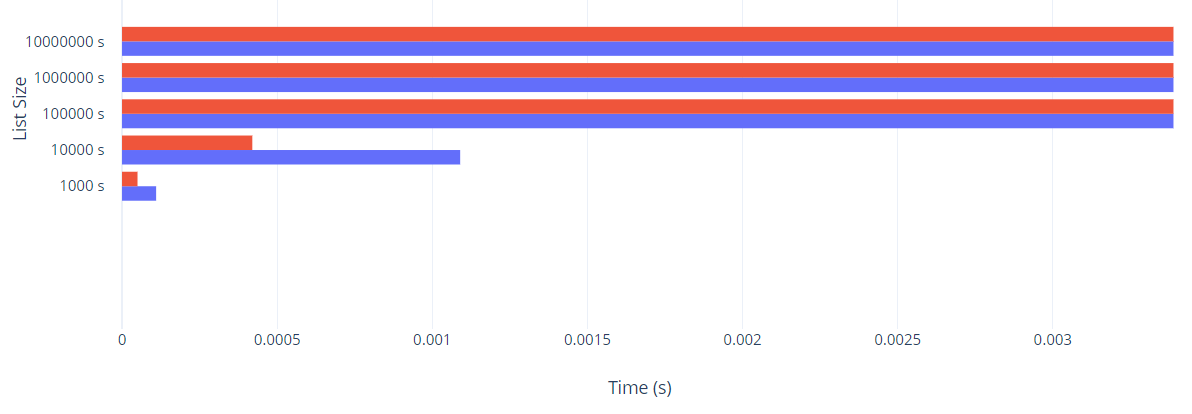
Zooming in on the smaller List Sizes:
Section 2 Results
| 1,000 | 10,000 | 100,000 | 1,000,000 | 10,000,000 | |
|---|---|---|---|---|---|
| For Loop | 0.00013 | 0.00122 | 0.01275 | 0.13191 | 1.33011 |
| List Comp | 0.00006 | 0.00062 | 0.00946 | 0.12563 | 0.81151 |
When the list was ordered (generated directly by a range function), the samples continued to behave in a fashion such that list comprehension was always faster (up to 2x as fast) than the for loop.
The general increase in time can be accounted due to the fact the range function was called, in contrast to iterating over a list that was generated before the function call. Interestingly, for the cases of 1,000,000 and 10,000,000 we can see that some optimization occurred where the results the final lists being generated were faster than that of using an unordered list.
Section 3 Results
| 1,000 | 10,000 | 100,000 | 1,000,000 | 10,000,000 | |
|---|---|---|---|---|---|
| For Loop | 0.00038 | 0.00355 | 0.04881 | 0.55235 | 5.73516 |
| List Comp | 0.00035 | 0.00331 | 0.04865 | 0.51484 | 4.80632 |
| Lambda in List Comp | 0.00044 | 0.00437 | 0.05306 | 0.62929 | 5.84127 |
| Map + Lambda + List Comp | 0.00041 | 0.00431 | 0.04886 | 0.71190 | 6.63414 |
When it comes to applying a simple function over a list of randomly assorted integers, it would seem that it makes little difference whether the list was generated via a list comprehension, or if the value was calculated and then appended to the list in a for loop.
Lambda functions within list comprehensions take up a similar amount of time compared to using map, to apply a lambda function on each element. These two methods take slightly longer than the for loop and list comprehension methods of building lists. When the list size being built is greater than 1,000,000 we can see that using map started to take more time than lambdas performed in list comprehensions.
Conclusion
If generating a list simply, it’s clear that list comprehension performs the fastest in time. If Lambda functions and Maps can be avoided, they should, and often times are also considered the less pythonic way (adding reading complexity to list comprehensions). When it comes to building a list simply, list comprehensions are twice as fast as building/appending to a list in a for loop (C/Java paradigm).
When it comes to performing some sort of function while generating a list (or after using map), the fastest method was to do so in the list comprehension but surprisingly, using a for loop took a negligible (albeit slightly more) amount of time - offering almost the same performance as list comprehension. Utilizing lambda functions padded more time, and using a map appeared to be the slowest method for large list cases (over 1,000,000). Using maps can be up to 2 seconds slower compared to list comprehensions for cases where the list is 10,000,000 elements long.
It can be observed that List Comprehension is always the faster paradigm.